What is Git rebase and how can it be used to resolve conflicts in a feature branch before merge?
According to me, you should start by saying git rebase is a command which will merge another branch into the branch where you are currently working, and move all of the local commits that are ahead of the rebased branch to the top of the history on that branch.
Now once you have defined Git rebase time for an example to show how it can be used to resolve conflicts in a feature branch before merge, if a feature branch was created from master, and since then the master branch has received new commits, Git rebase can be used to move the feature branch to the tip of master.
The command effectively will replay the changes made in the feature branch at the tip of master, allowing conflicts to be resolved in the process. When done with care, this will allow the feature branch to be merged into master with relative ease and sometimes as a simple fast-forward operation.
Now once you have defined Git rebase time for an example to show how it can be used to resolve conflicts in a feature branch before merge, if a feature branch was created from master, and since then the master branch has received new commits, Git rebase can be used to move the feature branch to the tip of master.
The command effectively will replay the changes made in the feature branch at the tip of master, allowing conflicts to be resolved in the process. When done with care, this will allow the feature branch to be merged into master with relative ease and sometimes as a simple fast-forward operation.
Q11. How do you configure a Git repository to run code sanity checking tools right before making commits, and preventing them if the test fails?
I will suggest you to first give a small introduction to sanity checking, A sanity or smoke test determines whether it is possible and reasonable to continue testing.
Now explain how to achieve this, this can be done with a simple script related to the pre-commit hook of the repository. The pre-commit hook is triggered right before a commit is made, even before you are required to enter a commit message. In this script one can run other tools, such as linters and perform sanity checks on the changes being committed into the repository.
Finally give an example, you can refer the below script:
#!/bin/sh
files=$(git diff –cached –name-only –diff-filter=ACM | grep ‘.go$’)
if [ -z files ]; then
exit 0
fi
unfmtd=$(gofmt -l $files)
if [ -z unfmtd ]; then
exit 0
fi
echo “Some .go files are not fmt’d”
exit 1This script checks to see if any .go file that is about to be committed needs to be passed through the standard Go source code formatting tool gofmt. By exiting with a non-zero status, the script effectively prevents the commit from being applied to the repository.
Now explain how to achieve this, this can be done with a simple script related to the pre-commit hook of the repository. The pre-commit hook is triggered right before a commit is made, even before you are required to enter a commit message. In this script one can run other tools, such as linters and perform sanity checks on the changes being committed into the repository.
Finally give an example, you can refer the below script:
#!/bin/sh
files=$(git diff –cached –name-only –diff-filter=ACM | grep ‘.go$’)
if [ -z files ]; then
exit 0
fi
unfmtd=$(gofmt -l $files)
if [ -z unfmtd ]; then
exit 0
fi
echo “Some .go files are not fmt’d”
exit 1This script checks to see if any .go file that is about to be committed needs to be passed through the standard Go source code formatting tool gofmt. By exiting with a non-zero status, the script effectively prevents the commit from being applied to the repository.
Q12. How do you find a list of files that has changed in a particular commit?
For this answer instead of just telling the command, explain what exactly this command will do so you can say that, To get a list files that has changed in a particular commit use command
git diff-tree -r {hash}
Given the commit hash, this will list all the files that were changed or added in that commit. The -r flag makes the command list individual files, rather than collapsing them into root directory names only.
You can also include the below mention point although it is totally optional but will help in impressing the interviewer.
The output will also include some extra information, which can be easily suppressed by including two flags:
git diff-tree –no-commit-id –name-only -r {hash}
Here –no-commit-id will suppress the commit hashes from appearing in the output, and –name-only will only print the file names, instead of their paths.
git diff-tree -r {hash}
Given the commit hash, this will list all the files that were changed or added in that commit. The -r flag makes the command list individual files, rather than collapsing them into root directory names only.
You can also include the below mention point although it is totally optional but will help in impressing the interviewer.
The output will also include some extra information, which can be easily suppressed by including two flags:
git diff-tree –no-commit-id –name-only -r {hash}
Here –no-commit-id will suppress the commit hashes from appearing in the output, and –name-only will only print the file names, instead of their paths.
Q13. How do you setup a script to run every time a repository receives new commits through push?
There are three ways to configure a script to run every time a repository receives new commits through push, one needs to define either a pre-receive, update, or a post-receive hook depending on when exactly the script needs to be triggered.
- Pre-receive hook in the destination repository is invoked when commits are pushed to it. Any script bound to this hook will be executed before any references are updated. This is a useful hook to run scripts that help enforce development policies.
- Update hook works in a similar manner to pre-receive hook, and is also triggered before any updates are actually made. However, the update hook is called once for every commit that has been pushed to the destination repository.
- Finally, post-receive hook in the repository is invoked after the updates have been accepted into the destination repository. This is an ideal place to configure simple deployment scripts, invoke some continuous integration systems, dispatch notification emails to repository maintainers, etc.
Hooks are local to every Git repository and are not versioned. Scripts can either be created within the hooks directory inside the “.git” directory, or they can be created elsewhere and links to those scripts can be placed within the directory.
Q14. How will you know in Git if a branch has already been merged into master?
I will suggest you to include both the below mentioned commands:
git branch –merged lists the branches that have been merged into the current branch.
git branch –no-merged lists the branches that have not been merged.
git branch –merged lists the branches that have been merged into the current branch.
git branch –no-merged lists the branches that have not been merged.
Continuous Integration questions
Now, let’s look at Continuous Integration interview questions:
Q1. What is meant by Continuous Integration?
I will advise you to begin this answer by giving a small definition of Continuous Integration (CI). It is a development practice that requires developers to integrate code into a shared repository several times a day. Each check-in is then verified by an automated build, allowing teams to detect problems early.
I suggest that you explain how you have implemented it in your previous job. You can refer the below given example:
I suggest that you explain how you have implemented it in your previous job. You can refer the below given example:
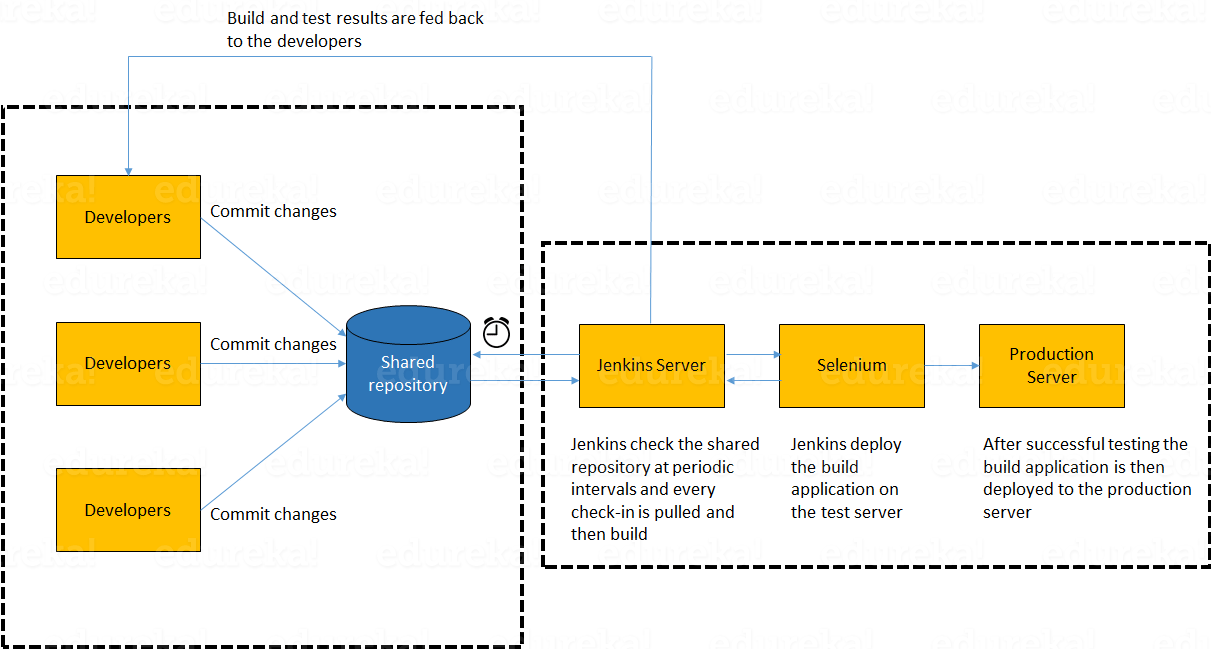
In the diagram shown above:
- Developers check out code into their private workspaces.
- When they are done with it they commit the changes to the shared repository (Version Control Repository).
- The CI server monitors the repository and checks out changes when they occur.
- The CI server then pulls these changes and builds the system and also runs unit and integration tests.
- The CI server will now inform the team of the successful build.
- If the build or tests fails, the CI server will alert the team.
- The team will try to fix the issue at the earliest opportunity.
- This process keeps on repeating.
Q2. Why do you need a Continuous Integration of Dev & Testing?
For this answer, you should focus on the need of Continuous Integration. My suggestion would be to mention the below explanation in your answer:
Continuous Integration of Dev and Testing improves the quality of software, and reduces the time taken to deliver it, by replacing the traditional practice of testing after completing all development. It allows Dev team to easily detect and locate problems early because developers need to integrate code into a shared repository several times a day (more frequently). Each check-in is then automatically tested.
Continuous Integration of Dev and Testing improves the quality of software, and reduces the time taken to deliver it, by replacing the traditional practice of testing after completing all development. It allows Dev team to easily detect and locate problems early because developers need to integrate code into a shared repository several times a day (more frequently). Each check-in is then automatically tested.
Q3. What are the success factors for Continuous Integration?
Here you have to mention the requirements for Continuous Integration. You could include the following points in your answer:
- Maintain a code repository
- Automate the build
- Make the build self-testing
- Everyone commits to the baseline every day
- Every commit (to baseline) should be built
- Keep the build fast
- Test in a clone of the production environment
- Make it easy to get the latest deliverables
- Everyone can see the results of the latest build
- Automate deployment
Q4. Explain how you can move or copy Jenkins from one server to another?
I will approach this task by copying the jobs directory from the old server to the new one. There are multiple ways to do that; I have mentioned them below:
You can:
You can:
- Move a job from one installation of Jenkins to another by simply copying the corresponding job directory.
- Make a copy of an existing job by making a clone of a job directory by a different name.
- Rename an existing job by renaming a directory. Note that if you change a job name you will need to change any other job that tries to call the renamed job.
Q5. Explain how can create a backup and copy files in Jenkins?
Answer to this question is really direct. To create a backup, all you need to do is to periodically back up your JENKINS_HOME directory. This contains all of your build jobs configurations, your slave node configurations, and your build history. To create a back-up of your Jenkins setup, just copy this directory. You can also copy a job directory to clone or replicate a job or rename the directory.
Q6. Explain how you can setup Jenkins job?
My approach to this answer will be to first mention how to create Jenkins job. Go to Jenkins top page, select “New Job”, then choose “Build a free-style software project”.
Then you can tell the elements of this freestyle job:
Then you can tell the elements of this freestyle job:
- Optional SCM, such as CVS or Subversion where your source code resides.
- Optional triggers to control when Jenkins will perform builds.
- Some sort of build script that performs the build (ant, maven, shell script, batch file, etc.) where the real work happens.
- Optional steps to collect information out of the build, such as archiving the artifacts and/or recording javadoc and test results.
- Optional steps to notify other people/systems with the build result, such as sending e-mails, IMs, updating issue tracker, etc..
Q7. Mention some of the useful plugins in Jenkins.
Below, I have mentioned some important Plugins:
- Maven 2 project
- Amazon EC2
- HTML publisher
- Copy artifact
- Join
- Green Balls
These Plugins, I feel are the most useful plugins. If you want to include any other Plugin that is not mentioned above, you can add them as well. But, make sure you first mention the above stated plugins and then add your own.



0 Comments
Post a Comment